深度解析 神经网络图像识别技术的演进与网络层数的关键影响
神经网络驱动的图像识别技术已成为人工智能领域最具突破性的进展之一。从人脸识别、自动驾驶到医疗影像分析,这项技术正以前所未有的速度重塑各行各业。其核心在于模拟人脑神经元连接方式的计算模型,通过多层次的数据处理,使计算机能够从原始像素中“理解”并分类图像内容。
神经网络的层数:模型深度的核心指标
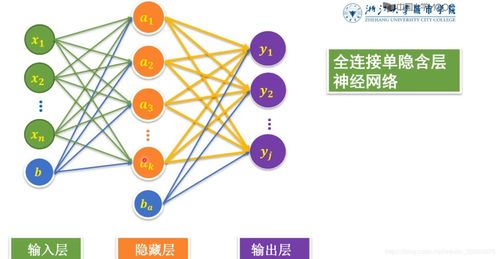
神经网络的“层数”是衡量其复杂性与能力的关键维度,通常指网络中的隐藏层数量。一个基础的神经网络包含输入层、若干隐藏层和输出层。
1. 浅层网络与深层网络的差异
- 浅层网络(如传统的感知机):通常仅有1-2个隐藏层。它们擅长学习简单的、线性的特征映射,但在处理如图像这类高度非线性、结构复杂的数据时,表达能力有限。
- 深层网络(即深度学习模型):隐藏层数量显著增加,可达数十甚至数百层(如ResNet、DenseNet)。每一层都能自动学习并提取不同抽象级别的特征——底层识别边缘、色彩等基础元素,中层组合成纹理、部件,高层则整合为完整的物体或场景。这种分层特征提取机制,正是其强大识别能力的源泉。
2. 如何“看”网络层数及其意义
- 结构可视化:通过模型架构图(如使用TensorBoard、Netron等工具)可直观看到层与层之间的连接关系与数量。
- 性能影响:增加层数通常能提升模型的表现力,使其能学习更复杂的模式,但这并非无止境。层数过多可能导致:
- 梯度消失/爆炸:误差在反向传播过程中逐层传递时可能衰减或激增,使训练变得极其困难。
- 过拟合:模型过度记忆训练数据中的噪声,导致在新数据上泛化能力下降。
- 计算成本飙升:需要更多的计算资源与时间。
- 现代解决方案:为了克服深度网络的训练难题,研究者引入了残差连接(ResNet)、批量归一化、深度可分离卷积等创新技术,使数百层的网络也能稳定、高效地训练。
网络技术的研究前沿与挑战
当前研究正从单纯追求“更深”的网络,转向构建“更智能”的结构:
- 轻量化与效率:在移动设备、嵌入式系统上部署模型的需求,催生了MobileNet、ShuffleNet等轻量级架构。它们通过深度可分离卷积等技术,在保持精度的同时大幅减少参数与计算量。
- 神经架构搜索(NAS):自动化机器学习的重要分支,利用算法自动搜索最优的网络层数、连接方式等超参数,旨在超越人工设计的架构,如EfficientNet系列模型便是NAS的杰出代表。
- 可解释性与鲁棒性:研究者正致力于揭示“黑箱”决策过程,增强模型对抗对抗性攻击的能力,并确保其在多样、真实场景下的可靠性。
- 跨模态与自监督学习:结合文本、声音等多模态数据训练,以及利用大量无标签数据通过自监督进行预训练,正推动图像识别走向更通用的视觉理解。
结论
神经网络的层数不仅是模型复杂度的标尺,更是其智能水平的体现。从浅层到深层的演进,标志着图像识别技术从“感知边缘”到“理解场景”的质的飞跃。未来的研究将更注重效率、鲁棒性与通用性的平衡,推动这项技术向着更强大、更可信、更普惠的方向持续发展。理解层数背后的原理与权衡,是有效应用和推进该领域研究的重要基石。
如若转载,请注明出处:http://www.dodotest.com/product/26.html
更新时间:2026-06-19 03:54:16